The Great IT Outage of 2024
What was supposed to be a routine security update turned into the worst IT outage in history and caused 8 million Windows machines to crash globally, revealing vulnerabilities in our digital infrastructure.

On July 19, 2024, an update to CrowdStrike's Falcon security software caused Blue Screen of Death (BSOD) errors on more than 8 million Windows machines globally, leading to crashes and boot failures. This incident, described as the "largest IT outage in history," exposed the vulnerabilities and gaps in our interconnected digital infrastructure.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25542517/2162028160.jpg)
The Technical Breakdown
CrowdStrike has released its root cause analysis, shedding light on the factors behind the massive outage. The problem originated from a defect in a configuration update for the Falcon sensor software. This update, designed to enhance the software's capability to gather telemetry on emerging threat techniques, inadvertently introduced a critical error. Specifically, the update was programmed to expect 20 input fields but actually provided 21, leading to an out-of-bounds memory read that caused system crashes on Windows machines.
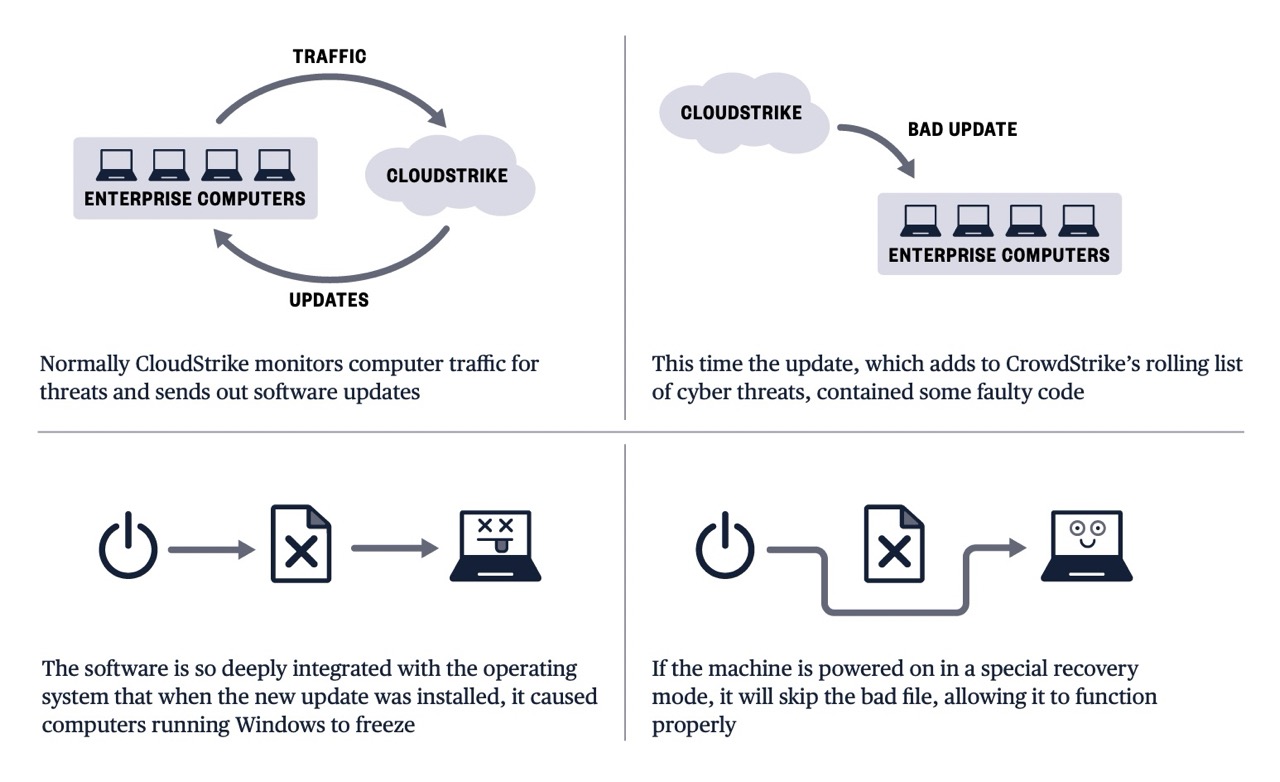
Both CrowdStrike's internal analysis and an independent third-party review confirmed that this bug was not exploitable by threat actors, indicating it was a non-malicious software error rather than a cyberattack. The update had bypassed adequate quality assurance checks, allowing the faulty code to pass through the testing phase and be deployed.
The issue was swiftly identified, and a fix was promptly rolled out after the update's release. However, many affected systems necessitated manual intervention to restore functionality, extending the outage for numerous organizations.
The Global Impact
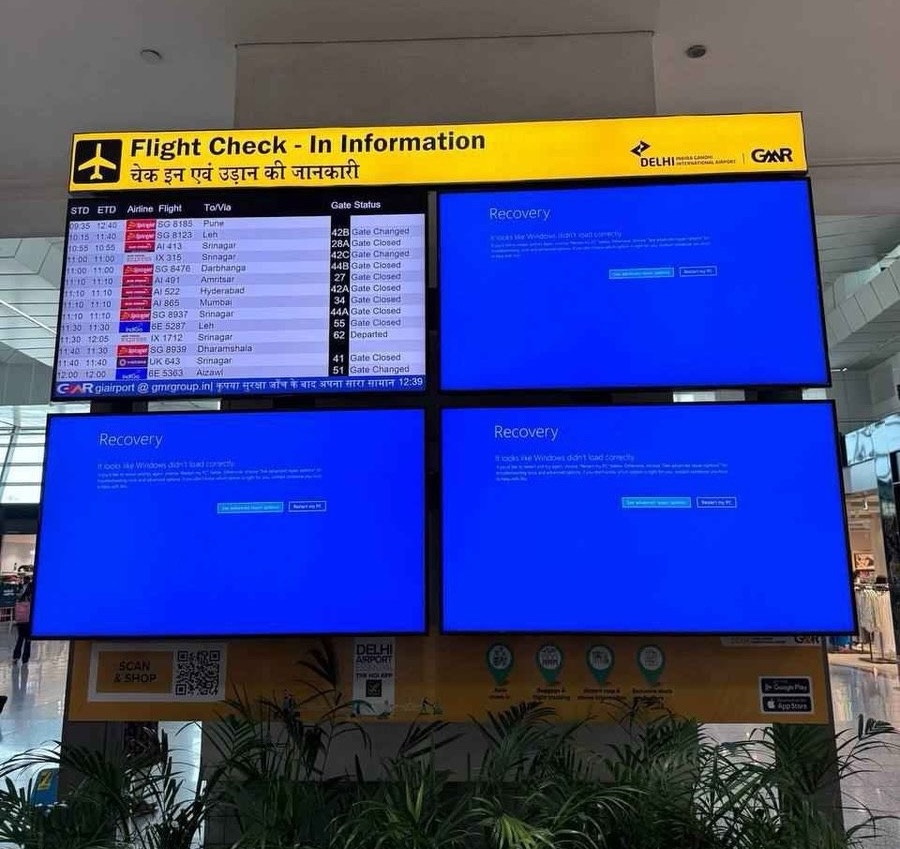
Critical sectors, including banks, airlines, TV broadcasters, and emergency services, were severely impacted. Major airlines like Delta, United, and American Airlines faced ground stops, and 911 call centers in Alaska and other states experienced outages. Fixing the problem was challenging as many affected machines couldn't even start up long enough to install the fix.
The simultaneous nature of the outage can be attributed to two factors: a) Many enterprise systems are configured to automatically apply security updates. b) CrowdStrike's cloud-based architecture allows for rapid deployment of updates across its client base.
The most severe aspect of this incident was that affected machines entered a boot loop. This made a fix challenging to apply, as many affected systems couldn't stay operational long enough to receive and install an update. This necessitated manual intervention in many cases, significantly slowing the recovery process.

Why Only Windows?
It's worth noting that only Windows systems were impacted in this incident. Linux and macOS systems operated as normal. CrowdStrike's disastrous software update just put a spotlight on how fragile Windows systems are in the enterprise world. The Falcon software running on Windows systems has full access to the kernel – the heart of the Windows operating system. Any mistake at this level, and you’ve essentially turned the entire OS into the computer equivalent of a broken clock.
Meanwhile, macOS and Linux systems received nearly unlimited free press at the expense of Microsoft. Why? The update wasn't even relevant to them, and their system architectures and protections mean software like CrowdStrike Falcon doesn't get that kind of VIP access to the OS kernel.
In fact, Apple specifically made changes to macOS which forces all third-party software to run outside of the kernel level. This means if an error caused Falcon on macOS to crash, it would not affect the operation of the system itself.
Since the global outage, Microsoft's Vice President of Windows Servicing and Delivery John Cable has hinted at future Windows versions adopting a stricter approach to kernel access for third-party software.
The Rough Path Forward
This whole fiasco proves how tricky it is to balance integrated security with system stability. It also begs more than a few questions. The CrowdStrike incident will likely be remembered as a turning point in our approach to cybersecurity and system reliability.
Why are secure systems like bank ATMs and airport check-in kiosks running heavyweight, error-prone systems like Windows, and all configured to receive automatic updates? Maybe it's time to rethink our update management strategies and consider the benefits of using simpler, more secure operating systems in distributed environments. If Tesla vehicles can use Linux to power high-resolution 3D visualizations, live camera feeds, driving systems, and A/C controls, why can't a simple bank ATM also use Linux?
Moreover, why has so much of the world outsourced their cybersecurity to a single company? Is it not the responsibility of every company using a computer to ensure its safety and reliability? This incident showcases that complacency is not an option in the digital realm. Only through sustained effort, rigorous testing, and proactive risk management can we hope to build a more resilient digital future capable of withstanding the challenges of our increasingly interconnected world.
Kartik's Newsletter
Science, tech, personal updates, no spam.